-

M&A
Q3 M&A Recap: Global Activity Sluggish, US Leads
-
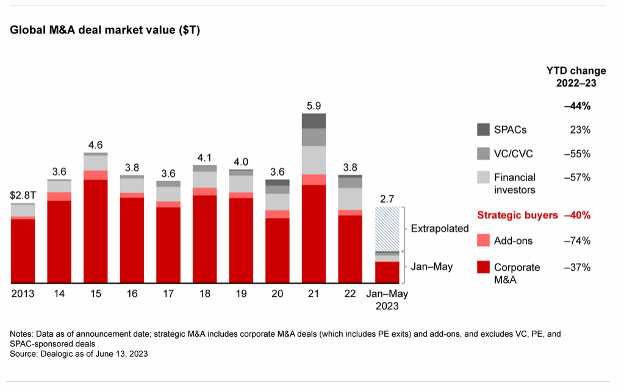
Venture Capital
Private Equity 2023 Mid-Year Recap: A Tough First Half
-

Virtual Data Room
Revolutionizing Board Communications with Virtual Data Rooms
-

M&A
Q2 2023 Yields Cautious Optimism for M&A
-

M&A
Q1 M&A: Running Against the Wind
-

M&A
Q1 Life Sciences: Resilient in a Changing Landscape
-

IPO
IPOs plummet in 2022. What Comes Next?
-
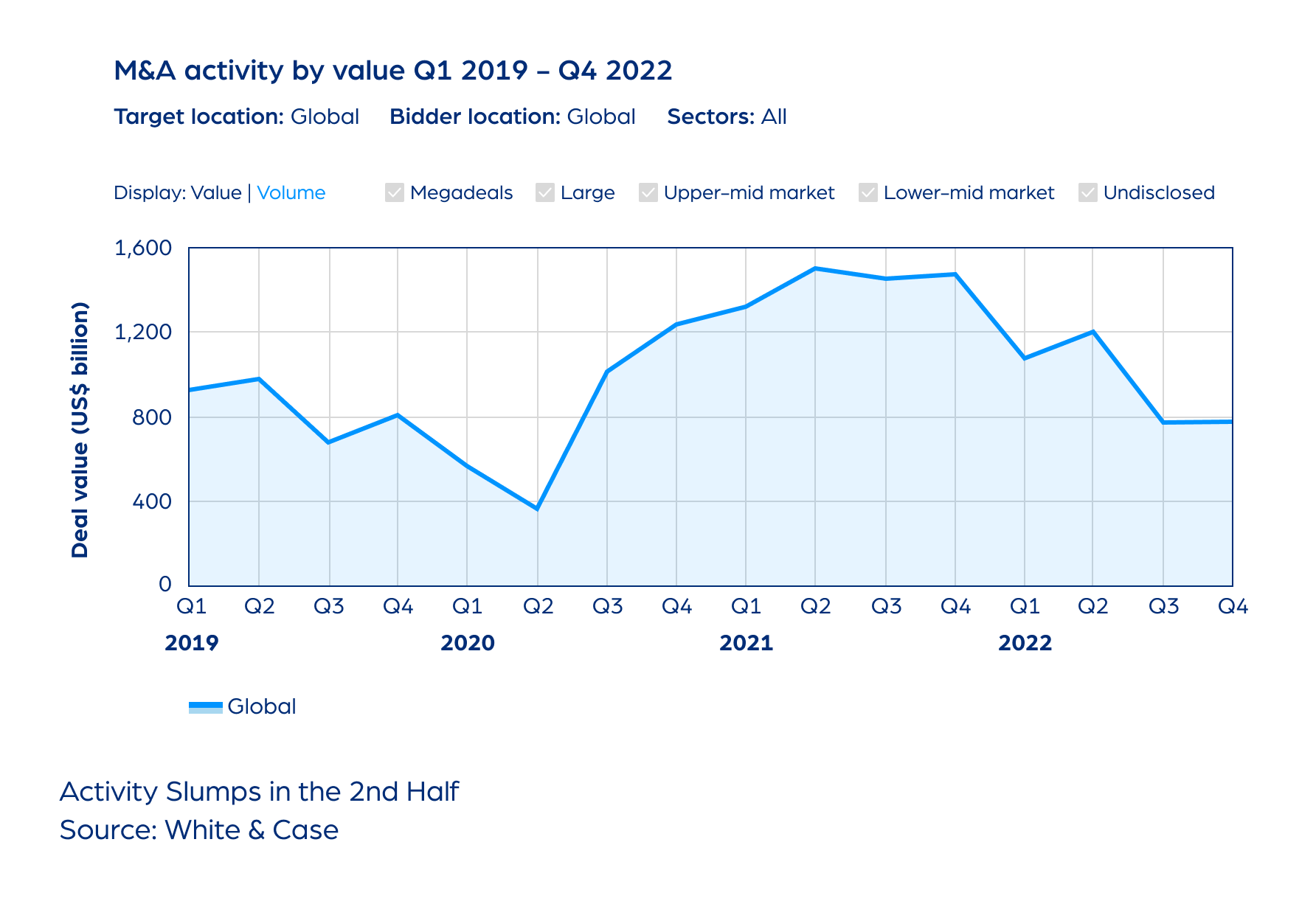
M&A
2022: Tough Environment, Resilient Market
-

M&A
Earnouts: Seeking Safety in a Transaction
-

Fundraising
5 Common Fundraising Questions Answered
-

Startups
Corporate Repository: Rethinking the Way You Do Business
-

Audits
Simplify Your Audit With a Virtual Data Room
current_page_num+2: 3 -
Ready to Get Started?
Start your free trial of SecureDocs today. Your data room will be available immediately—no need to talk to a salesperson.

